数据并行负载均衡#
dp_parallel_balance 是一种低侵入、易适配、可解释的工程方案,针对由定长打包 + 二次方 Attention 复杂度引起的 DP 负载不均衡问题。
它显著提升了大规模 DP 训练中的 GPU 利用率和线性扩展效率。
1. 背景与问题#
在大模型的数据并行(DP)训练中,我们通常采用定长打包,将若干样本拼接成固定的 token 长度(如 32K / 64K / 128K):
∑i len(samplei) = L
这保证了每个 DP rank 在 embedding、MLP、线性层等方面具有几乎相同的 O(n) 计算量和内存占用。
然而,Attention 是 O(n²) 的。其开销不仅取决于 pack 的总长度,还取决于 pack 内部的长度分布。
以 flash_attn_varlen 为例:
load(samplei) ∝ len(samplei)²
load(pack) ∝ ∑i len(samplei)²
因此,即使两个 DP rank 拥有总长度相同的 pack,其 Attention 工作量也可能差异巨大。
在训练中,负载较轻的 rank 必须在 All-Reduce 屏障处等待负载较重的 rank,产生落后者(straggler),降低 GPU 利用率并拖累全局吞吐量。 当 DP 规模 ≥ 32 时,该问题尤为突出。
2. 方案概述#
核心思想是在前向传播之前,根据样本的计算负载跨 DP rank 重新排序样本,使每个 rank 的负载相近。 预期收益:
缩短梯度同步等待时间
缓解落后者效应
提高训练吞吐量和线性扩展性
dp_parallel_balance 仅通过数据重排序实现:
与模型架构解耦
保持每次迭代的随机性 → 不影响收敛
主要逻辑在 CPU 上运行 → 无需额外 GPU 内核
3. 使用方法#
在训练启动脚本中添加以下参数:
--use-vlm-dp-balance
完整命令行选项#
参数 |
类型 |
默认值 |
说明 |
|---|---|---|---|
|
bool |
|
启用 VLM 级别的 DP 负载均衡 |
|
bool |
|
启用 ViT 编码器 DP 负载均衡(参见 ViT DP 负载均衡) |
|
list[int] |
|
用于预热分析的迭代索引;第一次迭代作为冷启动排除 |
|
float |
|
VLM 级别均衡的最大序列长度比率。限制每个 DP rank 的最大序列长度为(avg_len × ratio)。设为 |
|
float |
|
触发 VLM 级别均衡的最低不均衡比率阈值。当不均衡比率 < 阈值时跳过。 |
|
bool |
|
打印每次迭代的诊断信息:不均衡比率、每个 DP 的负载、重排序决策 |
支持的模型#
该功能支持以下模型系列:
InternVL — 解包/重打包
pixel_values、image_flags、input_ids、labels、loss_weightsVLM 系列(Qwen2-VL、Qwen3-VL 等) — 解包/重打包
tokens、labels、attn_mask、pixel_values_images、pixel_values_videos,以及image_grid_thw/video_grid_thw
模型系列从 --model-name / --model-family 自动检测。InternVL 和通用 VLM 路径共享相同的求解器,但数据打包/解包逻辑不同。
4. 核心设计#
4.1 架构概览#
系统通过 monkey-patching 集成到训练流水线中——无需修改 DataLoader 或模型代码:
patches.py— 启动时(exec_adaptation()),当--use-vlm-dp-balance启用时:用
_ResortQueueProxy包装 PyTorch 的_pin_memory_loop,拦截已 pin 的批次将 Megatron 的
RerunDataIterator替换为支持__iter__的扩展版本
pin_memory_hook.py—_ResortQueueProxy在预热完成后在 pin-memory 线程中调用reorder_data_across_dp(),透明地执行跨 DP 数据重排序train_hooks.py—train_step和training_log上的装饰器处理预热分析和系数广播
DataLoader → pin_memory_loop → _ResortQueueProxy → reorder_data_across_dp()
│
┌─────────────────────┼─────────────────────┐
▼ ▼ ▼
解包批次 求解重排序计划 重打包批次
(逐样本拆分) (LPT + 迭代优化) (重新分配)
4.2 预热:构建负载模型#
在最初几次迭代中(由 --vlm-dp-balance-warmup-iters 控制,默认为第 2-11 次迭代),我们分析每个 DP rank 的样本长度分布和迭代时间,然后拟合以下逐 rank 模型:
calc_loaddp = a·∑i len(samplei)² + b·∑i len(samplei) + c·sample_num
第 1 项 — 二次方 Attention 开销
第 2 项 — 线性层 / 通信开销
第 3 项 — 固定的内核启动开销
系数 a, b, c 通过最小化预测的最大 DP 负载与实测前向延迟之间的平方误差自动估计,使用 scipy.optimize.minimize 并施加非负约束。采用平滑的 softmax_max 近似来建模同步瓶颈(最慢的 DP rank 决定迭代时间)。
预热流程:
train_step_decorator— 预热期间每次训练步骤前,预览所有微批次并通过set_warmup_groups()记录每个 DP 的统计信息:(∑seq_len², ∑seq_len, seq_num)train_log_decorator— 每次预热步骤后,通过set_warmup_c1()记录前向计算延迟在预热结束后的下一次迭代,DP rank 0 通过
solve_computation_coef()拟合开销模型,然后将系数广播到所有 DP rank
注意: 第一次预热迭代被跳过(
iteration == vlm_dp_balance_warmup_iters[0]),以排除冷启动效应。
4.3 运行时:负载感知重排序#
预热结束后,每个批次通过以下流水线处理:
解包 — 将打包的批次拆分为单个样本(
depack_data_for_intern_vl或depack_data_for_vlm)收集 — 跨所有 DP rank 全收集每个样本的序列长度(
gather_sample_info_across_dp)估算 — 使用拟合模型计算每个样本的开销:
cost = a·len² + b·len + c求解 — 运行带迭代优化的 LPT 求解器(
solve_sample_dp_reorder_plan)重新分配 — 执行
all_to_all_single将张量移动到分配的 DP rank重打包 — 将重新分配的样本重新组装为打包的批次
4.4 LPT 求解器算法#
求解器(solve_sample_dp_reorder_plan)使用**贪心 LPT(最长处理时间优先)**算法,并进行迭代 Move/Swap 优化:
阶段 1 — 贪心分配:
将所有样本按开销降序全局排序
对每个样本,将其分配给当前总开销最低的 DP rank
在 VLM 模式下,遵守 pack 长度约束:每个 rank 的总序列长度不得超过
pack_len_ratio × avg_pack_len(默认比率:1.2,由--dp-balance-max-len-ratio-vlm控制)
阶段 2 — 迭代优化(最多 20 次迭代):
找到负载最大和最小的 DP rank
如果差距低于
swap_tolerance(默认 5%),则停止尝试两种操作:
Move:将开销最高的样本从最大负载 rank 转移到最小负载 rank
Swap:将最大负载 rank 上开销最高的样本与最小负载 rank 上开销最低的样本交换
选择更能减小最大-最小差距的操作(遵守 pack 长度约束)
跳过条件 — 满足以下条件时跳过重均衡(返回 None):
不均衡比率 < 阈值:当前分布已经均衡良好(默认阈值:0.2,由
--dp-balance-trigger-threshold-vlm控制)单个样本主导:最高单样本开销超过平均 DP 负载,意味着任何重新分配都无法显著改善均衡
4.5 跨微批次均衡#
当 num_microbatches > 1 时,_MicroBatchLoadTracker 累积同一迭代中各微批次的每个 DP 开销。求解器从之前的微批次接收 dp_historical_costs,使贪心分配和优化考虑总迭代负载,而不仅仅是当前微批次。这防止了每个微批次各自均衡但所有微批次在每个 rank 上的总负载偏斜的情况。
4.6 张量重新分配#
redistribute_tensor_helper 函数执行实际的跨 DP 通信:
从重排序计划构建发送/接收元数据
将所有要发送的张量展平为连续缓冲区
执行
all_to_all_single跨 DP rank 交换张量拆分接收到的缓冲区并应用
reconstruct_func恢复每个样本的张量形状
每种张量类型(LLM token、标签、像素值等)使用各自的 reconstruct_func 独立重新分配,因为不同张量每个样本的元素数量可能不同。
5. 诊断输出#
当启用 --dp-balance-verbose 时,系统在 DP rank 0、TP rank 0 上打印每次迭代的诊断信息:
跳过重均衡时:
[DP Balance][VLM] SKIP | reason: imbalance 0.1234 < 0.2
imbalance : 0.1234
load/dp : [1200.0, 1100.0, 1150.0, 1180.0]
cumulative: ViT_rebalance: 0/5 applied, VLM_rebalance: 3/10 applied
应用重均衡时:
[DP Balance][VLM] APPLY
before : imbalance=0.3456 load/dp=[1800.0, 1100.0, 1200.0, 1400.0]
after : imbalance=0.0234 load/dp=[1375.0, 1380.0, 1370.0, 1375.0]
cumulative: ViT_rebalance: 2/5 applied, VLM_rebalance: 8/10 applied
累积计数器跟踪整个训练过程中每种类型的重均衡被应用与跳过的次数。
6. 实验结果#
固定张量并行 = 4,InternVL 在 *** 数据集上。 平均 token / GPU / 秒(TGS)与 DP 规模的关系:
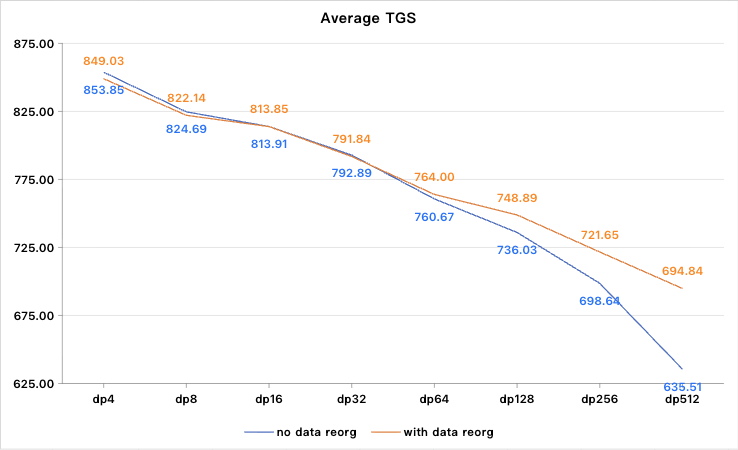
小规模 DP(4 / 8 / 16) – 无论是否重排序:TGS 几乎相同 → 不均衡可忽略。
大规模 DP(≥ 32) – 不重排序:TGS 因落后者效应快速下降。 – 使用
dp_parallel_balance: – Attention 负载在各 rank 间均衡 – All-Reduce 等待时间大幅减少 – 吞吐量下降得到显著抑制;收益随 DP 规模增长