异构并行#
1. 异构 TP 并行#
LoongForge 支持编码器和解码器的异构张量并行(TP)配置,即编码器和解码器可以使用不同的 TP 大小进行并行计算。
在此设计中,编码器和解码器被视为具有不同计算特性和资源需求的两个子模块。系统允许它们分别配置独立的张量并行组,从而在同一训练或推理任务中实现更细粒度的并行策略控制。
这种异构 TP 机制使模型能够根据编码器和解码器之间计算强度、参数规模、激活大小和通信模式的差异,灵活选择最合适的并行粒度,而不受整个模型统一 TP 配置的约束。
1.1 使用方法#
在对应模型的 vit.yaml 中设置 tensor-model-parallel-size 来指定 ViT TP 大小。例如,在 qwen3_vit 中添加 tensor_model_parallel_size: 2 来指定 ViT 的 TP 大小:
_target_: loongforge.models.encoder.Qwen3VisionModelConfig
num_layers: 27
hidden_size: 1152
kv_channels: 72
ffn_hidden_size: 4304
patch_size: 16
num_attention_heads: 16
num_query_groups: 16
image_size: [1344, 1344]
activation_func: ${act:gelu}
normalization: "LayerNorm"
add_bias_linear: true
add_qkv_bias: true
swiglu: False
group_query_attention: False
gated_linear_unit: False
position_embedding_type: "none"
bias_activation_fusion: False
deepstack_visual_indexes: [8, 16, 24]
num_position_embeddings: 2304
tensor_model_parallel_size: 2
model_type: "qwen3_vit"
在对应的 shell 脚本中指定解码器 TP 大小:
MODEL_PARALLEL_ARGS=(
--attention-backend flash
--tensor-model-parallel-size 4
--pipeline-model-parallel-size 2
--expert-model-parallel-size 8
--moe-token-dispatcher-type alltoall
--use-distributed-optimizer
# --sequence-parallel
--overlap-grad-reduce
--overlap-param-gather
--distributed-backend nccl
)
1.2 性能结果#
基于 qwen2.5vl7b 的测试,解码器 TP = 4,编码器 TP 分别为 1、2 和 4,不同设置表现出不同的性能特征。具体模型的性能需要实际测试。
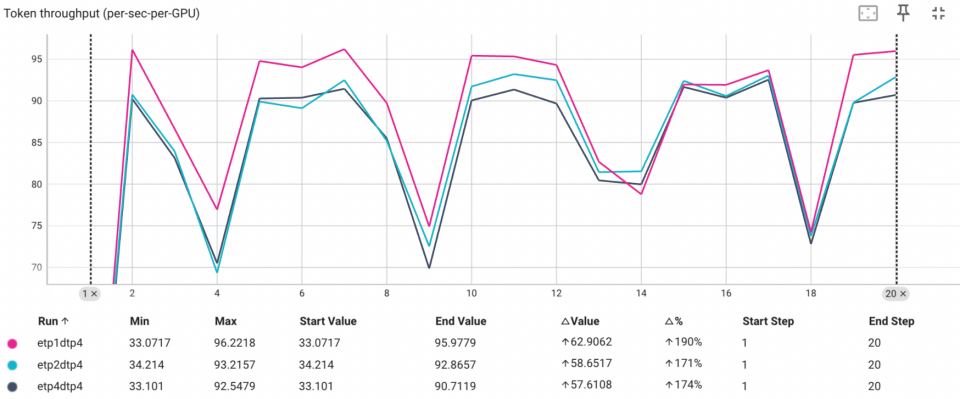
对于像 Vit(0.6b)这样的小规模编码器,在 qwen2.5vl 7b 模型中获得了 5% 的性能提升。
2. 异构 DP 并行#
仅靠异构张量并行(TP)不一定能提升端到端性能。因此,LoongForge 支持异构数据并行机制。核心思想是在对编码器和解码器应用异构 TP 后,我们可以利用多 GPU 并行,将不同输入送入不同的编码器副本,使它们同时计算,从而降低整体延迟。
2.1 使用方法#
在 shell 训练脚本中添加 --enable-encoder-hetero-dp 以启用异构数据并行:
MODEL_PARALLEL_ARGS=(
--attention-backend flash
--pipeline-model-parallel-size 2
--tensor-model-parallel-size 4
--use-distributed-optimizer
--overlap-grad-reduce
--overlap-param-gather
--distributed-backend nccl
--enable-encoder-hetero-dp
)
在对应模型的 vit.yaml 中添加 tensor_model_parallel_size: 1。目前启用异构 DP 时,仅支持编码器 TP 大小为 1。
_target_: loongforge.models.encoder.Qwen2VisionRMSNormConfig
num_layers: 32
hidden_size: 1280
kv_channels: 80
ffn_hidden_size: 3420
patch_size: 14
num_attention_heads: 16
num_query_groups: 16
image_size: [1344, 1344]
activation_func: ${act:silu}
add_bias_linear: true
add_qkv_bias: true
swiglu: true
gated_linear_unit: true
position_embedding_type: "none"
bias_activation_fusion: False
hidden_dropout: 0
attention_dropout: 0
normalization: "RMSNorm"
apply_rope_fusion: true
tensor_model_parallel_size: 1
model_type: "qwen2_5_vit"
注意:异构 DP 和异构 TP 对学习率敏感。建议使用较小的学习率,如 1e-5。
2.2 性能结果#
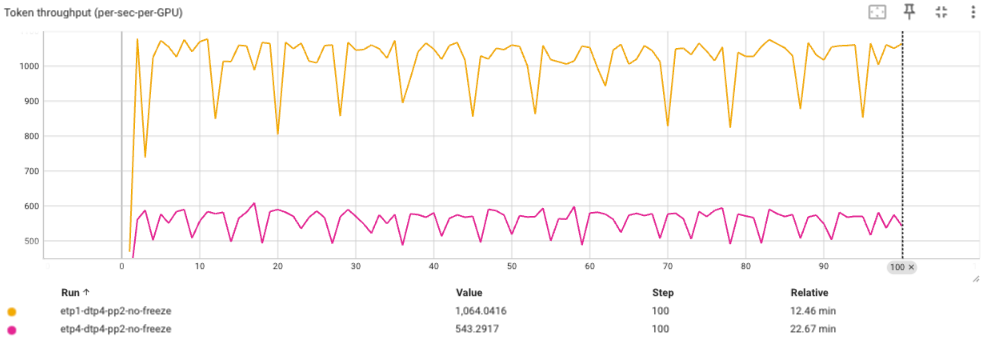
基于 qwen2.5vl7b 的测试,解码器 TP = 4、编码器 TP = 1,启用异构 DP 获得了显著的性能提升。
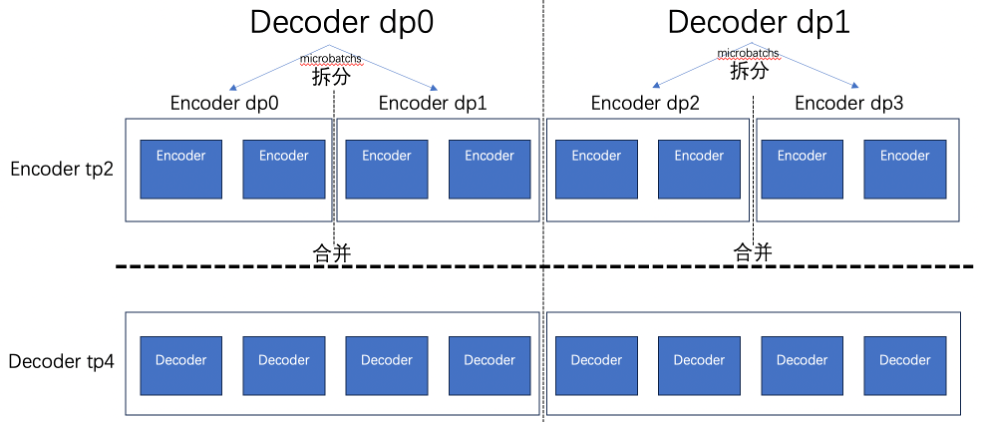
3. 全量异构 DP 并行#
第 2 节(异构 DP)允许编码器将 TP 组作为其数据并行组,使 TP 组中的每个 GPU 独立处理不同数据通过编码器,然后收集结果。但这仅限于 TP 维度。
全量异构 DP 将此思想扩展到整个模型并行组(TP × PP × CP)。模型并行组中的每个 GPU 独立处理不同的微批次通过编码器,然后在整个模型并行组中收集结果,再进入解码器。这通过利用所有模型并行 GPU 进行编码器数据并行来最大化编码器吞吐量。
3.1 工作原理#
在标准 VLM 训练中,每个微批次依次通过:
编码器(ViT):处理图像/视频 token
解码器(LLM):处理组合的文本 + 视觉 token
启用全量异构 DP 后:
编码器阶段:模型并行组中的每个 GPU(大小 = TP × PP × CP)独立处理不同的微批次通过编码器。然后 gather 操作将所有编码器输出收集到 rank 0。这意味着编码器实际上具有
TP × PP × CP的数据并行度。解码器阶段:标准的 Megatron 流水线并行/张量并行的前向-反向照常运行,使用预计算的编码器嵌入。
反向阶段:解码器反向完成后,梯度分散回模型并行组中的每个 GPU,编码器反向在每个 GPU 上本地运行。
3.2 使用方法#
步骤 1:在 vit.yaml 中设置编码器 TP 大小为 1#
全量异构 DP 要求编码器的 tensor_model_parallel_size: 1。在对应模型的 vit.yaml 中添加或设置此项:
_target_: loongforge.models.encoder.Qwen2VisionRMSNormConfig
num_layers: 32
hidden_size: 1280
kv_channels: 80
ffn_hidden_size: 3420
patch_size: 14
num_attention_heads: 16
num_query_groups: 16
image_size: [1344, 1344]
activation_func: ${act:silu}
add_bias_linear: true
add_qkv_bias: true
swiglu: true
gated_linear_unit: true
position_embedding_type: "none"
bias_activation_fusion: False
hidden_dropout: 0
attention_dropout: 0
normalization: "RMSNorm"
apply_rope_fusion: true
tensor_model_parallel_size: 1
recompute_granularity: full
recompute_method: uniform
recompute_num_layers: 1
model_type: "qwen2_5_vit"
步骤 2:在训练脚本中添加 --enable-full-hetero-dp#
MODEL_PARALLEL_ARGS=(
--attention-backend flash
--pipeline-model-parallel-size 2
--tensor-model-parallel-size 4
--use-distributed-optimizer
--overlap-grad-reduce
--overlap-param-gather
--distributed-backend nccl
--enable-full-hetero-dp
)
3.3 约束与注意事项#
编码器 TP 大小必须为 1:在 vit.yaml 中设置
tensor_model_parallel_size: 1。micro-batch-size 必须为 1:全量异构 DP 要求使用 packing 模式且
micro-batch-size=1。学习率敏感性:异构 DP 配置对学习率敏感。建议使用较小的学习率(如
1e-5)。不支持 CP:全量异构 DP 当前不支持上下文并行(CP)。启用
--enable-full-hetero-dp时,context-parallel-size必须设置为 1。